Условные выражения CASE. Условные выражения CASE Поисковая команда CASE
In this syntax, Oracle compares the input expression (e) to each comparison expression e1, e2, …, en.
If the input expression equals any comparison expression, the CASE expression returns the corresponding result expression (r).
If the input expression e does not match any comparison expression, the CASE expression returns the expression in the ELSE clause if the ELSE clause exists, otherwise, it returns a null value.
Oracle uses short-circuit evaluation for the simple CASE expression. It means that Oracle evaluates each comparison expression (e1, e2, .. en) only before comparing one of them with the input expression (e). Oracle does not evaluate all comparison expressions before comparing any of them with the expression (e). As a result, Oracle never evaluates a comparison expression if a previous one equals the input expression (e).
Simple CASE expression example
We will use the products table in the for the demonstration.
The following query uses the CASE expression to calculate the discount for each product category i.e., CPU 5%, video card 10%, and other product categories 8%
SELECT CASE category_id WHEN 1 THEN ROUND (list_price*0.05,2)-- CPU WHEN 2 THEN ROUND (List_price*0.1,2)-- Video Card ELSE ROUND (list_price*0.08,2)-- other categories END discount FROM ORDER BY |
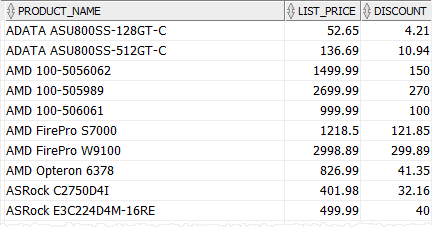
Note that we used the ROUND () function to round the discount to two decimal places.
Searched CASE expression
The Oracle searched CASE expression evaluates a list of Boolean expressions to determine the result.
The searched CASE statement has the following syntax:
CASE WHEN e1THEN r1 ,
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
Разберем каким образом получилось каждое возвращенное значение, а за одно вспомним конструкции базового синтаксиса оператора SELECT. Во-первых, т.к. мы в запросе не указали WHERE-условия, то итоги будут считаться для детальных данных, которые получаются запросом: SELECT * FROM Employees Т.е. для всех строк таблицы Employees. Для наглядности выберем только поля и выражения, которые используются в агрегатных функциях: SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent ,
Salary
FROM Employees
Это исходные данные (детальные строки), по которым и будут считаться итоги агрегированного запроса. Теперь разберем каждое агрегированное значение:
Подведем некоторые итоги:
Соответственно при задании с агрегатными функциями дополнительного условия в блоке WHERE, будут подсчитаны только итоги, по строкам удовлетворяющих условию. Т.е. расчет агрегатных значений происходит для итогового набора, который получен при помощи конструкции SELECT. Например, сделаем все тоже самое, но только в разрезе ИТ-отдела: SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent ,
Salary
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
Идем, дальше. В случае, если агрегатная функция возвращает NULL (например, у всех сотрудников не указано значение Salary), или в выборку не попало ни одной записи, а в отчете, для такого случая нам нужно показать 0, то функцией ISNULL можно обернуть агрегатное выражение: SELECT
SUM(Salary),
AVG(Salary),
-- обрабатываем итог при помощи ISNULL
ISNULL(SUM(Salary),0),
ISNULL(AVG(Salary),0)
FROM Employees
WHERE DepartmentID=10 -- здесь специально указан несуществующий отдел, чтобы запрос не вернул записей
Я считаю, что очень важно понимать назначение каждой агрегатной функции и то каким образом они производят расчет, т.к. в SQL это главный инструмент, который служит для расчета итоговых значений. В данном случае мы рассмотрели, как каждая агрегатная функция ведет себя самостоятельно, т.е. она применялась к значениям всего набора записей полученным командой SELECT. Дальше мы рассмотрим, как эти же функции применяются для вычисления итогов по группам, при помощи конструкции GROUP BY. GROUP BY – группировка данныхДо этого мы уже вычисляли итоги для конкретного отдела, примерно следующим образом:SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- данные только по ИТ отделу А теперь представьте, что нас попросили получить такие же цифры в разрезе каждого отдела. Конечно мы можем засучить рукава и выполнить этот же запрос для каждого отдела. Итак, сказано-сделано, пишем 4 запроса: SELECT "Администрация" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- данные по Администрации SELECT "Бухгалтерия" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- данные по Бухгалтерии SELECT "ИТ" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- данные по ИТ отделу SELECT "Прочие" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам В результате мы получим 4 набора данных:
Обратите внимание, что мы можем использовать поля, заданные в виде констант – "Администрация", "Бухгалтерия", … В общем все цифры, о которых нас просили, мы добыли, объединяем все в Excel и отдаем директору. Отчет директору понравился, и он говорит: «а добавьте еще колонку с информацией по среднему окладу». И как всегда это нужно сделать очень срочно. Мда, что делать?! Вдобавок представим еще что отделов у нас не 3, а 15. Вот как раз то примерно для таких случаев служит конструкция GROUP BY: SELECT
DepartmentID,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
Мы получили все те же самые данные, но теперь используя только один запрос! Пока не обращайте внимание, на то что департаменты у нас вывелись в виде цифр, дальше мы научимся выводить все красиво. В предложении GROUP BY можно указывать несколько полей «GROUP BY поле1, поле2, …, полеN», в этом случае группировка произойдет по группам, которые образовывают значения данных полей «поле1, поле2, …, полеN». Для примера, сделаем группировку данных в разрезе Отделов и Должностей: SELECT
DepartmentID,PositionID,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID,PositionID
SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND PositionID=2 -- ... SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4 А потом все эти результаты объединяются вместе и отдаются нам в виде одного набора:
Из основного, стоит отметить, что в случае группировки (GROUP BY), в перечне колонок в блоке SELECT:
И демонстрация всего сказанного: SELECT
"Строка константа" Const1, -- константа в виде строки
1 Const2, -- константа в виде числа
-- выражение с использованием полей участвуещих в группировке
CONCAT("Отдел № ",DepartmentID) ConstAndGroupField,
CONCAT("Отдел № ",DepartmentID,", Должность № ",PositionID) ConstAndGroupFields,
DepartmentID, -- поле из списка полей участвующих в группировке
-- PositionID, -- поле учавствующее в группировке, не обязательно дублировать здесь
COUNT(*) EmplCount, -- кол-во строк в каждой группе
-- остальные поля можно использовать только с агрегатными функциями: COUNT, SUM, MIN, MAX, …
SUM(Salary) SalaryAmount,
MIN(ID) MinID
FROM Employees
GROUP BY DepartmentID,PositionID -- группировка по полям DepartmentID,PositionID
Так же стоит отметить, что группировку можно делать не только по полям, но также и по выражениям. Для примера сгруппируем данные по сотрудникам, по годам рождения: SELECT CONCAT("Год рождения - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday) Рассмотрим пример с более сложным выражением. Для примера, получим градацию сотрудников по годам рождения: SELECT
CASE
WHEN YEAR(Birthday)>=2000 THEN "от 2000"
WHEN YEAR(Birthday)>=1990 THEN "1999-1990"
WHEN YEAR(Birthday)>=1980 THEN "1989-1980"
WHEN YEAR(Birthday)>=1970 THEN "1979-1970"
WHEN Birthday IS NOT NULL THEN "ранее 1970"
ELSE "не указано"
END RangeName,
COUNT(*) EmplCount
FROM Employees
GROUP BY
CASE
WHEN YEAR(Birthday)>=2000 THEN "от 2000"
WHEN YEAR(Birthday)>=1990 THEN "1999-1990"
WHEN YEAR(Birthday)>=1980 THEN "1989-1980"
WHEN YEAR(Birthday)>=1970 THEN "1979-1970"
WHEN Birthday IS NOT NULL THEN "ранее 1970"
ELSE "не указано"
END
Т.е. в данном случае группировка делается по предварительно вычисленному для каждого сотрудника CASE-выражению: SELECT ID, CASE WHEN YEAR(Birthday)>=2000 THEN "от 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989-1980" WHEN YEAR(Birthday)>=1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "ранее 1970" ELSE "не указано" END FROM Employees
Ну и конечно же вы можете объединять в блоке GROUP BY выражения с полями: SELECT DepartmentID, CONCAT("Год рождения - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday),DepartmentID -- порядок может не совпадать с порядком их использования в блоке SELECT ORDER BY DepartmentID,YearOfBirthday -- напоследок мы можем применить к результату сортировку Вернемся к нашей изначальной задаче. Как мы уже знаем, отчет очень понравился директору, и он попросил нас делать его еженедельно, дабы он мог мониторить изменения по компании. Чтобы, не перебивать каждый раз в Excel цифровое значение отдела на его наименование, воспользуемся знаниями, которые у нас уже есть, и усовершенствуем наш запрос: SELECT
CASE DepartmentID
WHEN 1 THEN "Администрация"
WHEN 2 THEN "Бухгалтерия"
WHEN 3 THEN "ИТ"
ELSE "Прочие"
END Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
ORDER BY Info -- добавим для большего удобства сортировку по колонке Info
Но ничего, со временем, мы научимся делать все красиво, чтобы выборка у нас не зависела от появления в БД новых данных, а была динамической. Немного забегу вперед, чтобы показать к написанию каких запросов мы стремимся прийти: SELECT ISNULL(dep.Name,"Прочие") DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName В общем, не переживайте – все начинали с простого. Пока вам просто нужно понять суть конструкции GROUP BY. Напоследок, давайте посмотрим каким образом можно строить сводные отчеты при помощи GROUP BY. Для примера выведем сводную таблицу, в разрезе отделов, так чтобы была подсчитана суммарная заработная плата, получаемая сотрудниками в разбивке по должностям: SELECT
DepartmentID,
SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера],
SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора],
SUM(CASE WHEN PositionID=3 THEN Salary END) [Программисты],
SUM(CASE WHEN PositionID=4 THEN Salary END) [Старшие программисты],
SUM(Salary) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
Можно конечно переписать и при помощи IIF: SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера], SUM(IIF(PositionID=2,Salary,NULL)) [Директора], SUM(IIF(PositionID=3,Salary,NULL)) [Программисты], SUM(IIF(PositionID=4,Salary,NULL)) [Старшие программисты], SUM(Salary) [Итого по отделу] FROM Employees GROUP BY DepartmentID Но в случае с IIF нам придется явно указывать NULL, которое возвращается в случае невыполнения условия. В аналогичных случаях мне больше нравится использовать CASE без блока ELSE, чем лишний раз писать NULL. Но это конечно дело вкуса, о котором не спорят. И давайте вспомним, что в агрегатных функциях при агрегации не учитываются NULL значения. Для закрепления, сделайте самостоятельный анализ полученных данных по развернутому запросу: SELECT
DepartmentID,
CASE WHEN PositionID=1 THEN Salary END [Бухгалтера],
CASE WHEN PositionID=2 THEN Salary END [Директора],
CASE WHEN PositionID=3 THEN Salary END [Программисты],
CASE WHEN PositionID=4 THEN Salary END [Старшие программисты],
Salary [Итого по отделу]
FROM Employees
И еще давайте вспомним, что если вместо NULL мы хотим увидеть нули, то мы можем обработать значение, возвращаемое агрегатной функцией. Например: SELECT
DepartmentID,
ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера],
ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора],
ISNULL(SUM(IIF(PositionID=3,Salary,NULL)),0) [Программисты],
ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старшие программисты],
ISNULL(SUM(Salary),0) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
GROUP BY в скупе с агрегатными функциями, одно из основных средств, служащих для получения сводных данных из БД, ведь обычно данные в таком виде и используются, т.к. обычно от нас требуют предоставления сводных отчетов, а не детальных данных (простыней). И конечно же все это крутится вокруг знания базовой конструкции, т.к. прежде чем что-то подытожить (агрегировать), вам нужно первым делом это правильно выбрать, используя «SELECT … WHERE …». Важное место здесь имеет практика, поэтому, если вы поставили целью понять язык SQL, не изучить, а именно понять – практикуйтесь, практикуйтесь и практикуйтесь, перебирая самые разные варианты, которые только сможете придумать. На начальных порах, если вы не уверены в правильности полученных агрегированных данных, делайте детальную выборку, включающую все значения, по которым идет агрегация. И проверяйте правильность расчетов вручную по этим детальным данным. В этом случае очень сильно может помочь использование программы Excel. Допустим, что вы дошли до этого моментаДопустим, что вы бухгалтер Сидоров С.С., который решил научиться писать SELECT-запросы.Допустим, что вы уже успели дочитать данный учебник до этого момента, и уже уверено пользуетесь всеми вышеперечисленными базовыми конструкциями, т.е. вы умеете:
Да, но они не учли, что вы пока не умеете строить запросы из нескольких таблиц, а только из одной, т.е. вы не умеете делать что-то вроде такого: SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
И так, как же можно воспользоваться вашими текущими знаниями и получить при этом еще более продуктивные результаты?! Воспользуемся силой коллективного разума – идем к программистам, которые работают у вас, т.е. к Андрееву А.А., Петрову П.П. или Николаеву Н.Н., и попросим кого-нибудь из них написать для вас представление (VIEW или просто «Вьюха», так они даже, думаю, быстрее поймут вас), которое помимо основных полей из таблицы Employees, будет еще возвращать поля с «Названием отдела» и «Названием должности», которых вам так недостает сейчас для еженедельного отчета, которым вас загрузил Иванов И.И. Т.к. вы все грамотно объяснили, то ИТ-шники, сразу же поняли, что от них хотят и создали, специально для вас, представление с названием ViewEmployeesInfo. Представляем, что вы следующей команды не видите, т.к. это делают ИТ-шники: CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- вернуть все поля таблицы Employees dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments pos.Name PositionName -- и еще добавить поле Name из таблицы Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID Т.е. для вас весь этот, пока страшный и непонятный, текст остается за кадром, а ИТ-шники дают вам только название представления «ViewEmployeesInfo», которое возвращает все вышеуказанные данные (т.е. то что вы у них просили). Вы теперь можете работать с данным представлением, как с обычной таблицей: SELECT *
FROM ViewEmployeesInfo
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM ViewEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
Т.е. для вас в данном случае, будто бы ничего и не поменялось, вы продолжаете так же работать с одной таблицей (только уже правильнее сказать с представлением ViewEmployeesInfo), которое возвращает все необходимые вам данные. Благодаря помощи ИТ-шников, детали по добыванию DepartmentName и PositionName остались для вас в черном ящике. Т.е. представление для вас выглядит так же, как и обычная таблица, считайте, что это расширенная версия таблицы Employees. Давайте для примера еще сформируем ведомость, чтобы вы убедились, что все действительно так как я и говорил (что вся выборка идет из одного представления): SELECT
ID,
Name,
Salary
FROM ViewEmployeesInfo
WHERE Salary IS NOT NULL
AND Salary>0
ORDER BY Name
Использование представлений в некоторых случаях, дает возможность значительно расширить границы пользователей, владеющих написанием базовых SELECT-запросов. В данном случае представление, представляет собой плоскую таблицу со всеми необходимыми пользователю данными (для тех, кто разбирается в OLAP, это можно сравнить с приближенным подобием OLAP-куба с фактами и измерениями). Вырезка с википедии. Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста. Как видите, уважаемые пользователи, язык SQL изначально задумывался, как инструмент для вас. Так что, все в ваших руках и желании, не отпускайте руки. HAVING – наложение условия выборки к сгруппированным даннымСобственно, если вы поняли, что такое группировка, то с HAVING ничего сложного нет. HAVING – чем-то подобен WHERE, только если WHERE-условие применяется к детальным данным, то HAVING-условие применяется к уже сгруппированным данным. По этой причине в условиях блока HAVING мы можем использовать либо выражения с полями, входящими в группировку, либо выражения, заключенные в агрегатные функции.Рассмотрим пример: SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
Т.е. данный запрос вернул нам сгруппированные данные только по тем отделам, у которых сумма ЗП всех сотрудников превышает 3000, т.е. «SUM(Salary)>3000».
Т.е. здесь в первую очередь происходит группировка и вычисляются данные по всем отделам: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам А уже к этим данным применяется условие указанно в блоке HAVING: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам HAVING SUM(Salary)>3000 -- 2. условие для фильтрации сгруппированных данных В HAVING-условии так же можно строить сложные условия используя операторы AND, OR и NOT: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Как можно здесь заметить агрегатная функция (см. «COUNT(*)») может быть указана только в блоке HAVING. Соответственно мы можем отобразить только номер отдела, подпадающего под HAVING-условие: SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х Пример использования HAVING-условия по полю включенного в GROUP BY: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. сделать группировку HAVING DepartmentID=3 -- 2. наложить фильтр на результат группировки Это только пример, т.к. в данном случае проверку логичнее было бы сделать через WHERE-условие: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- 1. провести фильтрацию детальных данных GROUP BY DepartmentID -- 2. сделать группировку только по отобранным записям Т.е. сначала отфильтровать сотрудников по отделу 3, и только потом сделать расчет. Примечание. На самом деле, несмотря на то, что эти два запроса выглядят по-разному оптимизатор СУБД может выполнить их одинаково. Думаю, на этом рассказ о HAVING-условиях можно окончить. Подведем итогиСведем данные полученные во второй и третьей части и рассмотрим конкретное месторасположение каждой изученной нами конструкции и укажем порядок их выполнения:
Конечно же, вы так же можете применить к сгруппированным данным предложения DISTINCT и TOP, изученные во второй части. Эти предложения в данном случае применятся к окончательному результату: SELECT
TOP 1 -- 6. применится в последнюю очередь
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
ORDER BY DepartmentID -- 5. сортировка результата
Как получились данные результаты проанализируйте самостоятельно. ЗаключениеОсновная цель которую я ставил в данной части – раскрыть для вас суть агрегатных функций и группировок.Если базовая конструкция позволяла нам получить необходимые детальные данные, то применение агрегатных функций и группировок к этим детальным данным, дало нам возможность получить по ним сводные данные. Так что, как видите здесь все важно, т.к. одно опирается на другое – без знания базовой конструкции мы не сможем, например, правильно отобрать данные, по которым нам нужно просчитать итоги. Здесь я намеренно стараюсь показывать только основы, чтобы сосредоточить внимание начинающих на самых главных конструкциях и не перегружать их лишней информацией. Твердое понимание основных конструкций (о которых я еще продолжу рассказ в последующих частях) даст вам возможность решить практически любую задачу по выборке данных из РБД. Основные конструкции оператора SELECT применимы в таком же виде практически во всех СУБД (отличия в основном состоят в деталях, например, в реализации функций – для работы со строками, временем, и т.д.). В последующем, твердое знание базы даст вам возможность самостоятельно легко изучить разные расширения языка SQL, такие как:
Если вы делаете первые шаги в SQL, то сосредоточьтесь в первую очередь, именно на изучении базовых конструкций, т.к. владея базой, все остальное вам понять будет гораздо легче, и к тому же самостоятельно. Вам в первую очередь, как бы нужно объемно понять возможности языка SQL, т.е. какого рода операции он вообще позволяет совершить над данными. Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции. Удачи вам в изучении и понимании языка SQL. Часть четвертая - |














